Medición Multidimensional de la Concentración de Población
Dr. Gerardo Núñez Medina1
1Investigador del Centro de Análisis e Información Estratégica para el Desarrollo Regional de la UNACH.
Contacto: gerardo.nm1@gmail.com
Versión en inglés
Descargar ePub
http://dx.doi.org/10.31644/IMASD.5.2014.a02
Resumen
La forma actual de medir la concentración de población se basa fundamentalmente en estimar el cociente entre personas y territorio en un momento dado del tiempo. Es fácil comprender que la forma de medir concentración está sujeta a variaciones repentinas de flujos migratorios. Este trabajo propone una nueva forma de medir los niveles de concentración de población en un territorio, haciendo uso de una gran cantidad de información referente a las características tanto de la población como de las viviendas, infraestructuras y servicios establecidos en dicho territorio. Proponiendo una nueva medida de concentración capaz de capturar múltiples elementos que le dan densidad al espacio y que a su vez permiten entender a las poblaciones como parte integral de un sistema que también le dan cuerpo, estructura y complejidad al territorio. De esta forma, el método diseñado, contempla distintas etapas de medición. Durante la primera se cuantifican los elementos tangibles como son la población y los elementos físicos que llenan los espacios y se cuantifican a través del método estadístico conocido como DP2. De esta forma es posible asignar un nivel de jerarquía de cada una de las localidades estudiadas, donde entendemos como localidad a la agrupación de una o más viviendas habitadas.
En una segunda etapa se identifican las relaciones entre conjuntos de localidades, es decir, se construyen sistemas de localidades los cuales son graficados como redes. Es a través de la identificación de relaciones que es posible establecer continuos de localidades como nuevos elementos en el sistema de localidades. Se entiende que las relaciones son también elementos que densifican el espacio, y que la posición de una localidad al interior del sistema modifica su grado de centralidad y por tanto debe incrementar de forma efectiva su nivel de concentración.
Finalmente, se propone una fórmula de cálculo del índice de concentración que utiliza como insumos la jerarquía de la localidad, las medidas de densidad de los sistemas de localidades y la superficie, tanto de la localidad como la que ocupa el sistema en su totalidad.
Palabras Clave: Concentración de población, densidad, sistemas de localidades.
Abstract
The current way of measuring the concentration of population is based primarily on the ratio between people and territory at a given time point. It is understandable that this way of measuring concentration is subject to sudden changes in migration flows. This paper proposes a new way of measuring the levels of population´s concentration in a territory using a lot of information on the characteristics of population, housing, infrastructure and services in that territory.
The paper proposes a new measure of concentration that can capture multiple elements that give the space density and in turn allow us to understand the populations as an integral part of a system that also give shape , structure and complexity to the territory . Thus, the method designed, provides for different measurement steps. During the first tangible elements such as the population and the physical elements that fill spaces and quantified using the statistical method known as DP2 quantified. This makes it possible to assign a hierarchy level of each of the sites studied, where locality to understand as a group of one or more occupied dwellings.
In a second step the relationship between sets of locations, that is, systems which are mapped locations as identified networks are built. It is through the identification of relationships that can be established continuous locations as new elements in the system locations. It is understood that relationships are also elements that densify the space, and that the position of a locality within the system changes its degree of centrality and therefore should effectively increase your concentration level.
Finally, a formula for calculating the concentration index using as inputs the hierarchy of the resort, the density measurements systems and surface locations of both the town and occupying the whole system is proposed.
Keywords: Concentration of population, density, measurements systems.
Introducción
La distribución espacial de la población, al interior del territorio, da origen al problema de medición de los niveles de concentración o dispersión, debido a que, en general, la distribución se realiza de forma heterogénea. La forma en que se distribuye la población en el territorio está estrechamente vinculada a factores de carácter histórico, económico, social, político, ambiental y cultural. Sin embargo, la concentración de población en grandes centros urbanos responde a una mayor disponibilidad de recursos, infraestructura y servicios, los cuales a su vez, determinan las condiciones de vida de la población y sus niveles de bienestar.
El desarrollo de una medida de concentración de población depende, en primer término, de la cantidad de personas que habitan en el territorio. Sin embargo, las dificultades técnicas para cuantificar en un espacio y momento dado a la población residente, así como lo efímero de su medición, hace necesario el desarrollo de nuevas técnicas. Lo anterior obliga a analizar la relación que existe entre población y territorio (mayor población implica mayor concentración), y complementarla con elementos menos dinámicos que permitan construir una aproximación más robusta.
No es sólo la cantidad de personas presentes en un territorio lo que lo hace más denso, deben considerarse elementos asociados a su composición demográfica, como su estructura por edad y sexo, su nivel educativo y su capacidad productiva, además de considerar elementos de carácter económico tales como la cantidad y calidad de equipamientos, viviendas, e infraestructuras, en términos no sólo de su número, sino de su importancia y pertinencia.
Así, un territorio es denso por su población, pero también, por todo lo que implica su presencia. Núcleos poblacionales numerosos involucran una mayor concentración de viviendas, de servicios y de equipamientos básicos como agua potable, electricidad, calles, escuelas y hospitales. Todo esto, sin hablar de las infraestructuras productivas y de comunicaciones, como fábricas, talleres, bancos, centros comerciales, puertos y aeropuertos. Es decir, para diseñar una nueva forma de medir la concentración de población, que sea robusta y estable en el tiempo, debe considerarse, además de la población, distintos elementos que den cuenta de manera exhaustiva de la densidad en el uso de suelo y de la velocidad con la que éste puede cambiar, lo que involucra la medición de flujos migratorios, estudiantiles, laborales y comerciales, entre otros.
El problema principal radica en que la población no permanece estática, lo que origina dos dificultades básicas: 1.- la medición de flujos poblacionales suele ser muy compleja en tanto más pequeña sea el área 2.- las mediciones pierden vigencia muy pronto debido a la dinámica misma de las migraciones y flujos laborales o commuters. Por tanto, se debe analizar la relación que existente entre población y territorio y complementarla con elementos menos dinámicos que permitan construir una medida más robusta del nivel de concentración.
El objetivo final es construir un indicador capaz de cuantificar los niveles de concentración de poblaciones agrupadas en distintos estratos de agregación administrativa y/o geográfica, utilizando bases teórico conceptuales que parten de los paradigmas como la teoría policéntrica, la teoría general de sistemas, la teoría de gráficas, el análisis de redes [7] y diversos métodos estadísticos multivariados como herramientas para reducir el número de variables y datos necesarios para la medición [4].
La metodología para el cálculo del índice de concentración de población ha sido dividida en etapas. A continuación se describe brevemente cada una de ellas, con base en los objetivos y las tareas a realizar, pero también considerando las limitaciones en relación con la disponibilidad y calidad de los datos e información oficial disponible para el caso de México.
La primera fase de la metodología consiste en identificar y analizar una serie de variables que caracterizan a las localidades de la República Mexicana. Las mismas están disponibles en línea (página oficial del INEGI) y provienen del último censo general de población y vivienda, además de información de los censos económicos y agrícolas generados por el Instituto Nacional de Estadística y Geografía.
El problema de concentración de población en el caso de México
México estaba conformado por 192,245 localidades habitadas al año 2010. Aunque en realidad el inventario de localidades rebasa las 280 mil.
La diferencia comprende localidades no habitadas. Del total de localidades habitadas, 139 mil son localidades con menos de 100 habitantes y con apenas el
2.2 por ciento de población nacional (2 millones 383 mil habitantes), lo que nos da una idea de la enorme dispersión de población.
Por otra parte, existen 36 localidades con más de 500 mil habitantes. Las mismas concentran el 27.8 por ciento de la población nacional
(poco más de 31 millones de habitantes), lo que nos da una idea de la enorme concentración de población. De esta forma, es posible
identificar un pequeño número de localidades con grandes concentraciones de población, pero también es fácil
identificar un gran número de localidades con poblaciones muy pequeñas. Este es un panorama muy general de la distribución de
la población a nivel nacional.
Otro factor que es importante analizar es el número y la velocidad con la que aparecen o desaparecen las localidades. Entre la ronda censal
de 2000 y 2010 desaparecieron 45,896 y surgieron 38,759 localidades. Es importante señalar que de las localidades que desaparecieron 44,581
eran menores de 100 habitantes, y un gran número de éstas sólo cambió de nombre, pero no fue posible distinguir entre ellas.
En este sentido, es importante señalar que el tamaño de la localidad es un factor fundamental para explicar la permanencia,
sobrevivencia y estabilidad en el tiempo de las localidades. 97 por ciento de las que desaparecieron eran menores de 100 habitantes.
También es necesario analizar las características de las localidades que no desaparecieron y aún más importante
conocer cuáles son las características de las localidades que además incrementaron de manera importante su tamaño.
¿Cuál fue la dinámica económica, demográfica y social que siguieron para asegurar su permanencia en el tiempo? ¿Existieron elementos físicos o infraestructuras que puedan explicar su evolución? En el siguiente apartado construiremos los indicadores que darán cuenta de los elementos asociados a las principales características presentes en todas las localidades del país.
El resto del documento detalla una nueva metodología que ofrece una medida de concentración de población a nivel de localidad para la
República Mexicana, a través del cálculo de un indicador cuyo objetivo es cuantificar la densidad de población considerando
una gran cantidad de información referente a las viviendas, equipamientos, infraestructuras y servicios disponibles, así como sus
características en términos de calidad y nivel de accesibilidad.
Algoritmo para la medición de los niveles de concentración de población
La metodología para el desarrollo de un modelo de concentración-dispersión gira entorno al concepto de policentrismo, enmarcado dentro de la teoría general de sistemas, y evaluando a través de funciones matemáticas desarrolladas con el fin de cuantificar los conceptos de centralidad y dispersión desde una perspectiva sistémica. De modo que un sistema no será visto de forma abstracta o cualitativa sino que se dará una aproximación matemática del enfoque tradicional.
El algoritmo para medir los niveles de concentración de población en México se desarrollará en las siguientes fases:
1. Asignar un nivel de jerarquía a cada localidad del país.
2. Identificar centros como zonas anormalmente densas, es decir, con un nivel de jerarquía por arriba de dos desviaciones estándar de la media de la región de análisis.
3. Definir continuos de localidades centrales, como aquellas zonas del espacio donde el continuo de edificaciones rebasa el límite de la localidad, con la finalidad de identificar centros rurales, centros urbanos y centros metropolitanos entre otros.
4. Establecer un área de influencia para cada centro, a través de la identificación de flujos entre localidades.
5. Tipificar redes de localidades como sistemas formados por centros, subcentros y localidades, en distintos niveles de agregación. Se tratará de sistemas metropolitanos, urbanos, rurales o dispersos.
6. Asignar una jerarquía a cada sistema.
7. Calcular la medida de concentración de población.
Jerarquía de localidades
La jerarquía de localidad es un indicador de la importancia que tiene una localidad en relación con las localidades de su entorno, permite comparar el nivel de primacía de una localidad de 800 habitantes respecto de otra con igual número de personas, pero con diferente composición demográfica, social y económica. Es decir, el indicador permitirá discriminar dos o más localidades a partir de un conjunto muy amplio de variables agrupadas en, cuando menos, cuatro dimensiones básicas:
1. Dimensión poblacional
• Población total
• Nivel educativo
• Acceso a servicios de salud
• Edad media de la población
• Dependencia demográfica
• Migración
2. Estructura y composición de los hogares
• Total de hogares
• Tamaño medio de los hogares
• Proporción de hogares con jefatura femenina
• Proporción de hogares unipersonales
• Número medio de hijos por hogar
3. Dimensión de Viviendas (número y calidad de bienes en las viviendas)
• Total de viviendas
• Calidad de las viviendas (techos, pisos,...)
• Servicios en las viviendas (agua, electricidad,...)
• Bienes en las viviendas (refrigerador,...)
4. Equipamiento de la localidad
• Acceso a carretera
• Transporte público
• Red de agua potable
• Red de drenaje
• Recolección de basura
• Alumbrado público
• Calles pavimentadas
• Plaza o jardín
• Oficina de registro civil
• Agencia municipal
5. Infraestructura económica de la localidad
• Infraestructura de servicios (número de hospitales, escuelas,..)
• Infraestructura de comunicaciones (u.e. dedicadas a comunicaciones)
• Infraestructura productiva (sector primario, secundario, terciario)
El desarrollo del indicador de jerarquía de localidades requiere del apoyo de técnicas estadísticas de análisis multivariado, las cuales tienen como objetivo resumir grandes cantidades de variables, que suelen estar correlacionadas matemática y conceptualmente. Las técnicas estadísticas tienen la capacidad de reducir y capturar la mayor parte de la complejidad observada y generar nuevos conceptos conocidos como variables latentes. Su diseño conduce a la generación de indicadores simples y robustos.
En lo referente al desarrollo de indicadores, las técnicas estadísticas que mejor se adaptan al tipo de requerimientos señalados son: El análisis de componentes principales (ACP) y El análisis de distancias (DP2). Para el diseño del indicador de jerarquía de localidades hemos optado por el uso de la técnica de análisis de distancias DP2 cuya principal característica consiste en identificar y descartar aquellas relaciones no significativas.
La técnica DP2 tiene como finalidad desarrollar indicadores de carácter sintético con base en el concepto de distancia donde el coeficiente de correlación parcial, entre el componente i-ésimo y el j-ésimo, es una medida que refleja el valor absoluto de la diferencia entre el conjunto de indicadores ideales (es decir, una medida patrón, que no necesariamente se observa en la realidad) con relación a un conjunto de indicadores simples u observados, estandarizado por el inverso de la desviación estándar del indicador observado. La información redundante es descartada mediante la inclusión del coeficiente de correlación parcial.
Dado que las variables que componen cada indicador de jerarquía de localidad tienen diferentes unidades de medida y escala, se empleará el Análisis de Distancia (DP2) con la finalidad de reducir el efecto producido por la magnitud de las diferentes escalas o métricas. Sin embargo, la aplicación de la DP2 demanda del cumplimiento de una serie de supuestos que aseguren la consistencia del resultado, partiendo de la adecuada selección y calidad de los datos, junto con el seguimiento de los niveles de correlación entre las variables involucradas. Los supuestos a considerar son completitud y objetividad, lo que implica que los datos que se utilicen deben ser una representación objetiva de la variable a modelar, libre de juicios de valor o predicciones subjetivas sobre la misma.
La técnica DP2 transforma todos los componentes en unidades comparables asegurándose de no modificar el orden del indicador de la siguiente forma:
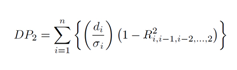
Se debe entender que el empleo de la técnica DP2 tiene como objeto estimar el valor de un índice de jerarquía que resuma
las dimensiones de los indicadores y de todas sus variables asociadas, de acuerdo a un modelo conceptual que para el caso de la medida de
concentración se entiende en términos de combinaciones lineales de las variables expuestas con anterioridad, es decir:
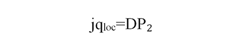
El cálculo de la jerarquía de localidad exige de la medición y evaluación de datos a nivel de localidad.
La información para su estimación puede obtenerse de los microdatos del Censo General de Población y Vivienda,
los Conteos de Población, así como de datos agregados a nivel de AGEB provenientes de los Censos Económicos y
de los Censos Agrícolas, información proporcionada por el Instituto Nacional de Estadística y Geografía (INEGI).
Identificación de centros y subcentros
La forma tradicional de identificar centros y subcentros urbanos está dada por la metodología establecida por Roca y Marmolejo [12],
la cual realiza un análisis de la distribución espacial de la densidad de uso de suelo, de la que se desprenden cuatro métodos:
1. Análisis del manto de densidades y detección de disrupciones locales con el uso del SIG;
2. Utilización de un conjunto de umbrales de densidad y masa;
3. Identificación, desde una perspectiva econométrica, de posibles subcentros de zonas con residuos significativamente positivos en una regresión en donde la variable dependiente es la densidad de empleo y la independiente la distancia al distrito central de negocios (CBD por sus siglas en inglés), y
4. Estimación de modelos no paramétricos con el uso de la regresión local o geográficamente ponderada, con el objetivo de detectar picos de densidad una vez que el manto ha sido ajustado localmente, teniendo en cuenta dos dimensiones, y considerando el efecto de las zonas cercanas.
Una segunda vertiente de orden funcionalista explica que los centros o subcentros no sólo son zonas anormalmente densas, sino que son nodos a partir de los cuales se estructuran las relaciones funcionales, entre nodos, con el CBD y con el resto del sistema.
El criterio funcionalista permite caracterizar a los centros una vez detectadas las relaciones de jerarquía, complementariedad y sinergia. De forma que la identificación de los centros y subcentros, será el trabajo más delicado en función de la capacidad para cuantificar las medidas de centralidad y flujo de cada uno de los centros, utilizando el valor de las relaciones establecidas en términos de su complementariedad y sinergia, a partir de toda la información disponible para establecer el tipo, la frecuencia, intensidad y sentido de las relaciones.
Existen algunas otras definiciones de centro, tanto de orden funcional como de orden económico, tales y como pueden verse en [29, 32]:
1. Zona con densidad de empleo significativamente mayor que su vecindad.
2. Un área que tiene un efecto significativo en la densidad.
3. Represente el elemento vertebrador de un subsistema urbano dentro de la estructura metropolitana.
La manera en la que identificaremos los centros potenciales, estará fundamentada en la idea de que un centro es un área del espacio anormalmente densa, la cual es capaz de estructurar las relaciones con las localidades vecinas. Para lograr la identificación objetiva de los centros potenciales emplearemos el análisis de autocorrelación espacial, mismo que va a permitir la identificación de localidades de alta concentración (alta jerarquía) a partir de la relación que guarda la jerarquía de cada localidad consigo misma y con el espacio.
El análisis de autocorrelación espacial es capaz de identificar el grado en que las localidades de una unidad geográfica son similares a otras localidades en unidades geográficas cercanas. Es decir, es capaz de identificar puntos o zonas calientes rodeadas de zonas calientes, y viceversa, zonas frías rodeadas de zonas frías. Esta característica es fundamental para identificar las localidades con alta jerarquía rodeadas de localidades con jerarquías altas, las cuales desde luego serán identificadas como centros o subcentros.
La centralidad de una localidad se detectará a través de la autocorrelación espacial, medida a partir del índice de Moran tanto de manera global:
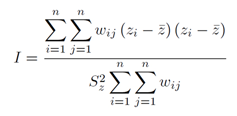
Como de manera local:
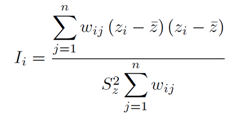
Donde W
ij es el ponderador que indica la relación de contigüidad entre las unidades espaciales i y j. El cual puede ser un indicador de vecindad o una métrica asignada.
La dependencia local estará definida por una concentración, en un lugar del espacio global, de valores especialmente altos de la jerarquía de localidad en comparación con el valor medio de la misma.
La mera observación en un mapa de la distribución de una variable en el espacio permite captar de forma intuitiva la existencia de patrones de comportamiento espacial, esta información será siempre subjetiva y altamente dependiente de, por ejemplo, el número de intervalos establecidos para la representación de dicha variable en el mapa. Por eso, resulta fundamental contar con una combinación de medidas o instrumentos estadísticos capaces de detectar la presencia significativa de autocorrelación espacial (global y/o local).
El diseño de medidas de centralidad de las localidades en una estructura sistémica, se realizará a través de las medidas tradicionales de centralidad. En general, la forma de medir la concentración de un sistema es por medio de medidas, donde la centralidad es un atributo de los nodos (localidades), asignado en función de su posición estructural, es decir, no se trata de un atributo intrínseco (como el ingreso) sino que depende directamente de la forma del sistema. Por ejemplo, en un sistema con forma de estrella, el nodo central ocupa un valor de centralidad máximo, mientras que los nodos de las puntas toman valores de centralidad menores. Es decir, la centralidad dependerá, además de la medida de autocorrelación espacial, de la posición que ocupe el centro con respecto de los subcentros y al resto de localidades.
Definición de continuos de localidades
Durante la fase de identificación de continuos de localidades se construirán nuevas unidades de análisis a partir de la agrupación de localidades contiguas. Estas nuevas unidades son agrupaciones de localidades que comparten al menos una frontera física común, donde el continuo de edificaciones no se rompe o donde el número de infraestructuras que conectan las localidades hacen posible pensar que estas forman un continuo (dada la cantidad e intensidad de flujos) y es posible además encontrar evidencia de niveles de autocorrelación espacial similares entre las localidades del continuo. En este punto se propone una nueva tipología de conjuntos de localidades de vaya, más allá de la simple separación de lo urbano y lo rural.
Los continuos de localidades se establecerán a través de un algoritmo de identificación que toma en cuenta:
• La contigüidad espacial
• El nivel jerárquico de la localidad
• Los niveles observados de autocorrelación espacial
• La presencia de infraestructuras
• Las rupturas geográficas
El algoritmo de identificación de continuos está desde luego determinado por lo que se entiende por contigüidad espacial y la definición de vecindad que utiliza los polígonos que conforman las unidades territoriales de análisis. En este momento, debe señalarse que existe una gran cantidad de localidades rurales, sobre todo dispersas, cuya delimitación aún no ha sido realizada, por lo que no se cuenta con un polígono definido para las mismas.
Las pruebas de autocorrelación espacial local permiten detectar agrupaciones o clusters de variables que están espacialmente referenciadas. Permiten además contrastar la presencia de zonas de dependencia espacial dentro de un área general o local por medio de los denominados Indicadores Locales de Asociación Espacial o LISA por sus siglas en inglés.
Los Indicadores Locales de Asociación Espacial generan para cada punto un indicador de significancia de la agrupación. La suma de significancias de todos los puntos, en el área de estudio, es proporcional al indicador global de asociación espacial correspondiente a esa área. Es decir, descompone el índice global de autocorrelación y verifica la contribución de cada unidad espacial a la formación del valor general, permitiendo capturar de forma simultanea el grado de asociación espacial y la heterogeneidad resultante del aporte de cada unidad espacial.
La prueba de autocorrelación espacial busca contrastar la hipótesis nula de no autocorrelación local (H
o), para lo cual asume como hipótesis alternativa que la variable a contrastar tiene una distribución aleatoria.
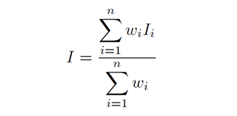
Donde w
i es, como antes, el ponderador de vecindad o distancias.
Se propone el uso de la prueba LISA, debido a que algunos estadísticos globales de retardo espacial pueden ocultar patrones de autocorrelación espacial, mientras que LISA tiene la capacidad de detectarlos y además mostrar su ubicación, además puede descomponer los resultados globales en locales y descubrir patrones locales ocultos en datos que contienen patrones globales.
Una vez identificados los continuos se procederá a asignar un nivel de jerarquía para los mismos, como la suma de las jerarquías de las localidades que lo integran, más un factor de ajuste debido a la integración de relaciones. El cual se definirá en la etapa de identificación de redes de localidades como sistemas.
Tipología de localidades
Las localidades rurales se definen como aquéllas de menos de 2500 habitantes. Esta medición de lo rural y urbano no permite reconocer la heterogeneidad que caracteriza la estructura de dichas poblaciones. El problema es análogo a querer definir el arcoíris como la combinación del blanco y el negro.
La jerarquía de localidades es un índice multidimensional que permite capturar la heterogeneidad en distintos estadíos de desarrollo de las localidades, sin embargo, la pregunta a responder es ¿Cuál es el umbral mínimo en términos de infraestructura que debe alcanzar una localidad para poder ser considerada como urbana? Más allá de intentar resolver este tipo de cuestionamientos, me enfocaré en proponer una nueva tipología de localidades, la cual busca capturar sus distintas etapas de desarrollo.
Propuesta de tipología de localidades:
1. Localidad dispersa no amanzanada (un conjunto de viviendas habitadas sin servicios ni acceso a caminos).
2. Caserío no amanzanado (se trata de un conjunto de viviendas con acceso a algunos servicios y a terracería o algún otro camino).
3. Localidad amanzanada con caseríos dispersos (es una localidad con un núcleo de viviendas identificable, más viviendas dispersas).
4. Centro micro regional (se trata de una localidad completamente amanzanada cuya área construida han cubierto al menos un 75 por ciento de la localidad).
5. Centro (meso) regional (se trata de una localidad que ha rebasado sus límites y se encuentra en fase de conurbación con otras localidades).
6. Centro macro regional (se trata de un centro consolidado en términos de equipamiento, infraestructura y servicios que abarca cuando menos dos localidades conurbadas).
7. Metrópolis (una urbe consolidada).
8. Megalópolis (la conurbación de varias urbes consolidadas).
Establecimiento del área de influencia
Una vez identificados el centro y los subcentros, ya sea como una única localidad o como un continuo de localidades, el siguiente paso consiste en la definición de su área de influencia, la cual estará en función, desde luego, de su nivel de jerarquía y del número e importancia de las localidades con las que comparta una misma zona geográfica.
La definición del área de influencia deberá estimarse para todos los centros y subcentros identificados, es decir, que alcanzaron un nivel mínimo de jerarquía para optar por la categoría de centro o subcentro. Sin embargo, es necesario precisar que el nivel de jerarquía será siempre relativo al entorno.
En este punto es necesario definir un algoritmo que permita identificar un área de influencia para localidades identificadas como centrales en un ámbito local en función de elementos como:
1. Localización del centro (coordenadas)
2. Nivel de jerarquía del Centro
3. La distancia entre localidades y el centro
4. Atractivo del centro
5. Posición del centro en la red
6. Región geográfica de pertenencia
7. Fronteras políticas
8. Rupturas geográficas
9. Jerarquía de las localidades vecinas
En general, se establecerá el área de influencia de un centro o subcentro como la zona de atracción a partir del Modelo de
aglomeración/desaglomeración de tipo gravitatorio propuesto por Roca C, Josep y Marmolejo, C. (2010) tal como:

En donde:
A y B= jerarquía de la localidad (intensidad del atractivo o de la atracción)
M= localidades cercanas al centro o subcentro
i= localidad atraída
j= localidad a tractora (centro o subcentro)
k
1 y k
2 =constantes de ajustes del modelo
d
ij = distancia entre las dos localidades
r
1 y r
2= la velocidad a la que la atracción del centro se diluye con la distancia
El objetivo es identificar las áreas de influencia de zonas metropolitanas, grandes ciudades, y zonas urbanas, pero también de pequeños
centros localizados en áreas rurales, y en zonas dispersas. Además se buscará validar a través de la identificación de
relaciones de todo tipo la existencia de dicha zonas de influencia.
Una definición general de policentrismo se asocia a la idea de que al interior de un área urbana de carácter metropolitano se genera
una estructura multinuclear, a partir del surgimiento de núcleos urbanos periféricos. Es decir, una ciudad, generalmente tiene un centro
identificable y al mismo tiempo coexisten otros subcentros urbanos, con los que se establece una serie de relaciones complementarias o de competencia.
En este sentido es clara la relación que existente entre la teoría policéntrica y el desarrollo de la teoría de sistemas.
De esta forma el modelo de medición mapea las características del modelo policéntrico (centros, subcentros y flujos) a una
estructura sistémica cuantificable a partir de la definición de un sistema compuesto por subsistemas (conjuntos de localidades) y por
relaciones entre las mismas [3]. Además, cada uno de los diferentes subsistemas deberá ser traducido a un gráfico que modelará
el sistema a través de una red la cual servirá de base para construir las funciones de concentración y flujo, además de permitir
la identificación visual de los sistemas.
Caracterizar redes de localidades como sistemas
En este punto se van a identificar los sistemas que conforman cada centro o subcentro, así como su complejidad y nivel de concentración, por lo que será fundamental conocer el nivel de integración, estructura y jerarquía. El objetivo es definir los diferentes sistemas que se observan en el contexto nacional y estatal. Cada uno de los sistemas está formado por un centro y un conjunto de localidades que interactúan con dicho centro, o por un centro, un conjunto de subcentros y un conjunto de localidades al interior de su área de influencia.
La importancia y nivel de jerarquía de cada uno de los sistemas dependerá de la preponderancia de su centro, el número de localidades que integran el sistema y de la cantidad de relaciones y flujos presentes.
Una red es la representación gráfica de un sistema y puede definirse como un conjunto de objetos sumados a un conjunto de conexiones. Un conjunto de relaciones jerárquicas o uno formado por relaciones no jerárquicas forman una red, y lo que los diferencia es la dirección de los flujos, en el primero se trata de relaciones verticales y de dominancia, y en el segundo, de relaciones de tipo horizontales o de igualdad.
En general el análisis de una red se fundamenta en el reconocimiento y evaluación de relaciones entre nodos (un nodo es una localidad, un centro, o un subcentro). La caracterización de flujos permite identificar una red, así como su ámbito de acuerdo a las oportunidades y limitaciones producto de las características de la misma estructura de relaciones. La morfología de una red puede identificarse a partir de los siguientes elementos:
1. Anclaje o localización: punto inicial o de partida de la red (referencia), el cual determina la estructura de oportunidad, determina la facilidad para acceder a los recursos de otras localidades;
2. Accesibilidad: fuerza con la cual el comportamiento de una localidad está influenciada por su relación con otras. Es posible calcular dos tipos de accesibilidad. Por proximidad, que se refiere a la menor distancia relacional con otras localidades. O por intermediación que indica las localidades que se hallan a la menor distancia.
3. Densidad: está en función del número de vínculos, y
4. Rango: en todos los sistemas algunas localidades tienen acceso directo a otras. Un rango de primer orden está dado por el número de localidades en contacto directo con la localidad sobre la que se localiza la red.
La identificación y caracterización de flujos en la red (sistema de localidades) se realizará con base en los siguientes elementos:
• Contenido: se refiere al contenido del flujo de comunicación a través de la red;
• Dirección: hay casos en los que los vínculos son recíprocos. Sin embargo, hay relaciones donde el flujo circula con más intensidad hacia un sentido de la relación o son relaciones de una sola dirección;
• Duración: las redes tienen un determinado período de vida;
• Intensidad: esta se puede entender como el grado de implicación de los actores vinculados entre sí, y
• Frecuencia: es necesaria una relativa repetición de los contactos entre los actores vinculados para que tal vínculo perviva.
Los indicadores de flujo se estimarán en términos directos e indirectos con información propia de las localidades y de flujos carreteros, corridas de autobuses, flujo de bienes y servicios y flujo de personas. Además, se considerarán elementos como:
• Distancia, tiempo y costos de transportación
• Integración a cadenas productivas
Dado que los elementos tangibles a detectarse dentro de cada red son nodos definidos como localidades, centros o subcentros, estos se cuantifican como:
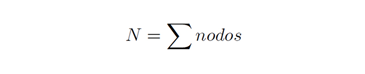
Una vez conocidos los nodos y sus relaciones, es posible calcular el tamaño de la red, como:
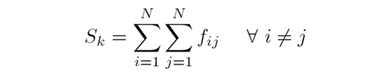
Donde f
ij representa el flujo entre los nodos i e j, i indica el nodo de origen y j indica el nodo de destino.
La densidad de una red se define como el número de relaciones efectivas (tamaño de la red) dividido por el número de relaciones posibles, excluyendo la diagonal principal de la matriz de relaciones, (es decir, se excluyen las relaciones de un nodo consigo mismo). La densidad es por lo tanto un índice que varía entre 0 y 1. Donde el 0 representa una red con densidad nula y 1 representa una red totalmente conectada.
 Una vez identificados los elementos y medidas básicas de la red es posible definir tipologías generales:
Una vez identificados los elementos y medidas básicas de la red es posible definir tipologías generales:
1. Atendiendo a la naturaleza de la externalidad de una red es posible identificar redes de complementariedad y redes de sinergia.
a. Redes de complementariedad: se dan entre centros especializados y complementarios, interconectados a través de interdependencias de mercado, de manera que la división de funciones entre estos nodos asegura un área de mercado suficientemente grande para cada centro y posibilita que se alcancen economías de escala y de aglomeración.
b. Redes de sinergia: se dan entre centros con una orientación productiva similar, que cooperan entre ellos de forma no programada. En este tipo de centros el concepto clave es que la sinergia se obtiene de la cooperación, y por tanto, las externalidades las provee la misma red.
2. Atendiendo al tipo de articulación se puede hablar de redes jerárquicas, policéntricas y equipotenciales.
a. Redes jerárquicas o redes de jerarquía, surgen a partir de la idea o el modelo de lugar central. Las relaciones entre los nodos de la red son asimétricas, y el sistema está conformado por polígonos, es decir, es posible identificar patrones de contigüidad espacial entre los nodos y por lo tanto pueden predecirse posibles relaciones espaciales entre nodos vecinos.
b. Redes policéntricas o de especialización local estable. Las relaciones de intercambio entre nodos pueden basarse en la complementariedad o en la sinergia, aunque pueden ser fuertemente asimétricas, incluso de dominancia-dependencia. En este caso, las funciones urbanas se dividen entre varios nodos, en combinaciones de diversos tipos y dimensiones. No obstante, su distribución tampoco es casual, sino que los nodos se organizan buscando conseguir unas economías de aglomeración determinadas.
c. Redes equipotenciales surgen cuando las relaciones entre los nodos son simétricas o casi simétricas y no obedecen a un patrón. Las funciones urbanas se distribuyen de modo casual entre los nodos de la red. La actividad no sigue un patrón definido de localización, es decir las actividades se distribuyen de forma aleatoria entre nodos, pero sobre una base de complementariedad, sin que exista un centro definido en la red.
En la práctica, la forma de detectar la tipología de una red se realiza a través de modelos de gravedad, mientras que las estimaciones para la búsqueda de complementariedades se realizan con metodologías enfocadas a determinar la existencia de redes.
Los modelos de gravedad utilizan datos de flujos para identificar redes de sinergia, mientras que los modelos de complementariedad utilizan estimaciones basadas en la búsqueda de datos de stock para la detección de redes de complementariedad.
En general, la detección de redes de sinergia, a partir de un modelo de gravedad, se realiza con datos de movilidad laboral y distancias medidas como tiempos de desplazamiento entre cada nodo. El modelo de gravedad relaciona las masas con las distancias (número de lugares de trabajo localizados en la localidad) y estima fundamentalmente relaciones de jerarquía.
Los procedimientos para detectar redes de sinergia o de complementariedad incluyen los que se estiman empleando:
• Datos de flujos desagregados por sectores o actividades para determinar los pares de localidades entre los que existen fuertes intercambios sinérgicos y complementarios.
• Identifican la estructura de la red y superponiendo especializaciones de las localidades, de manera que puedan establecerse (entre cada par de localidades conectadas por una relación de red) relaciones de complementariedad o sinergia, con base en dicha especialización. Este procedimiento utiliza datos de flujo y de stock.
Si las localidades entre las que existe una relación de red tienen la misma especialización, se considera que la relación de red es sinérgica, y en caso de que cada una tenga una especialización diferente, la relación se considera de tipo complementaria.
Asignar un nivel jerárquico a cada sistema
La teoría de sistemas proporciona el instrumental matemático básico para el trabajo con redes. El instrumental se basa en el cálculo matricial y en la elaboración de indicadores que revelan las características de la red y los nodos que la componen.
Las matrices básicas de la teoría de redes son la matriz de adyacencia, la matriz de accesibilidad y la matriz de distancia.
La matriz de adyacencia indica cuando existe una conexión directa entre dos nodos de la red en un grafo. Es una matriz cuadrada y binaria, donde un valor 0 indica la ausencia de relaciones entre dos nodos, y un valor 1 indica que dos nodos están directamente relacionados.
La matriz de accesibilidad, indica si un nodo de la red está conectado con otro, sea de forma directa o indirecta. La matriz de accesibilidad también puede ser ponderada (no binaria) cuando muestra el número total de conexiones entre pares de nodos.
La matriz de distancia determina la ruta más corta que atraviesa el mínimo número de arcos para desplazarse entre los dos nodos.
A partir de estas matrices pueden calcularse, como ya se estableció en el punto ocho, estadísticos como el tamaño y la densidad de la red. A partir del tamaño y la densidad de la red es posible asignar un nivel de jerarquía de cada uno de los sistemas detectados como la suma cada uno de los nodos que la componen multiplicado por su jerarquía más la densidad de la red.
Medida de concentración
Finalmente, para calcular el índice de concentración (IC) de los elementos definidos al interior de los sistemas de localidades o de las localidades mismas, se diseñó una medida en el sentido de un modelo de densidad no paramétrico, el cual contempla, a cada uno de los elementos señalados en los puntos anteriores.
El IC de una localidad se estimará directamente como el cociente de la jerarquía de la localidad, multiplicada por el número e intensidad de las relaciones que mantiene la localidad con las localidades del sistema de referencia, dividido por el área que ocupa. Es decir:
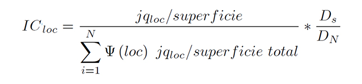
Donde la función ψ está definida como:
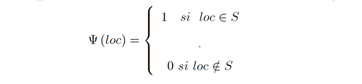
Por otra parte, el IC puede ser estimado para un sistema S (un sistema de localidades dispersas, o un sistema de ciudades) como:
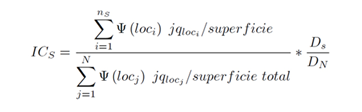
Adicionalmente, puede estimarse el IC de un área geográfica específica, como un estado o un municipio,
o cualquier otra superficie, a partir de la siguiente expresión:
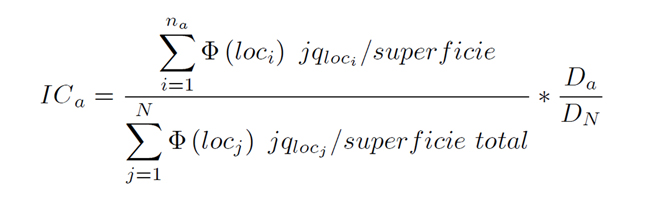
Donde la función Φ está definida como:

En general, se decidió emplear esta forma de medición debido a que los procedimientos no paramétricos pueden ser aplicados a
cualquier tipo de distribuciones, sin ningún tipo de hipótesis sobre la forma de la densidad subyacente. Además,
este tipo de métrica tiene la capacidad de ajustarse a casos donde la distribución es del tipo multimodal.
Conclusiones
Es importante cambiar la concepción dicotómica de los núcleos poblacionales.
Como se ha dicho anteriormente, definir los conglomerados poblacionales como rurales y urbanos,
es equivalente a querer explicar el arcoíris con el blanco y el negro. Implica ignorar la realidad de una gran cantidad de
núcleos cuyo estadío de desarrollo los coloca en cualquiera de las tipologías propuestas en el apartado correspondiente.
Por otra parte, es también importante destacar que un núcleo poblacional es más que sólo la aglomeración de personas,
por lo que su definición debe incluir las infraestructuras físicas y los espacios donde fluyen de forma tangible e intangible una gran
cumulo bienes y servicios que dinamizan y densifican el área geográfica que habitan. De forma que, la definición y
medición de la concentración poblacional que se propone involucra una gran cantidad de dimensiones, y cada una de ellas busca
capturar una forma de densificación del espacio distinta.
Finalmente, la metodología propuesta asigna un grado de jerarquía o importancia a cada núcleo poblacional,
ésta es una medición intermedia de la concentración, cuya utilidad práctica desborda los alcances de
la investigación. La finalidad última es generar una medida de concentración la cual se logra al relativizar
el peso específico de cada localidad, con respecto al ámbito geográfico en el que se encuentra inserto.
Referencias
[1] Aldous J. y Wilson R. (2000). Graphs and Applications, An Introductory Approach. Springer-Verlag, Berlin.
[2] Barry Lee (1979). Introducing Systems Analysis and Design. Vols. I, II. National Computer Center, Manchester.
[3] Beineke W, y Wilson J, (1988). Selected Topics in Graph Theory. Academic Press, London.
[4] Box, G., W. Hunter, and J. S. Hunter (1978). Statistics for Experimenters: An Introduction to Design, Data Analysis, and Model Building. Wiley, New York.
[5] Boix, R. (2003). Redes de ciudades y externalidades. Tesis doctoral, mayo 2003, Departamento de Economía Aplicada, Universidad Autónoma de Barcelona.
[6] Cerda. J.; Marmolejo C. (2002). De la Accesibilidad a la Funcionalidad del territorio: una nueva dimensión para entender la estructura y el crecimiento urbano residencial de las áreas metropolitanas de Santiago (Chile) y Barcelona (España). EURE, Revista Latinoamericana de Estudios Urbano Regionales.
[7] Dale-Johnson, D.; Brzeski,W.(2001). Spatial Regression Analysis of Comercial Land Prices Gradients. Working Paper.2001-1008.USC LUSK Center of Real Estates, University of Southern California.
[8] Fischer, M.; Getis, A. (Eds.). (2010). Handbook of Spatial Analysis: Software Tools, Methods and Applications. Springer-Verlag Berlín Heidelberg.
[9] Friedman, J., Hastie, T., Tibshirani, R. (2008). The Elements of Statistical Learning. Data Mining, Inference and Prediction, Chapter 2: Overview of Supervised Learning, Springer. 2nd edition.
[10] García-López, M.A. (2007). Estructura Espacial del Empleo y Economías de Aglomeración: El Caso de la Industria de la Región Metropolitana de Barcelona. Architecture, City & Environment, 4.
[11] Goodchild, Michael. (1987). A Spatial Analytical Perspective on Geographical Information Systems. International Journal of Geographical Information Systems, Vol. 1, No. 4, Department of Geography, University of Western Ontario, London, Ontario, Canada.
[12] Kleinberg J. (2008). The Convergence of Social and Technological Networks. Communications of the ACM.
[13] Knoke D. and Yang S. (2008). Social Network Analysis. Number 07-154 in Quantative Applications in the Social Sciences. SAGE Publications, Thousand Oaks, CA.
[14] Lin, Y., and Y.-H. Ma (1990). General feedback systems. Int. J General Systems, 18, No 2.
[15] Lin, Y. and R. Port (1998). Centralizability and its existence. Math. Model. Sci. Comput, 14, No 23.
[16] Lin, Y. (2002). General Systems Theory A Mathematical Approach. Kluwer Academic Publishers, Pennsylvania.
[17] Lin, Y., and E. A. Vierthaler (1998). A systems identification of social problems and its application to public issues of contention during the twentieth century. Math. Model. Sci. Comput.
[18] Lin, Y., and S.-T. Wang (1998). Developing a mathematical theory of computability which speaks the language of levels. Math. Comput. Model.
[19] Marmolejo, C. (2008). La localización intrametropolitana de las actividades de la información. Libro electrónico, Centro de documentación Fundación CIDOB Aula Barcelona.
[20] Marmolejo, C. (2009). Vuelta a la Barcelona Postindustrial: análisis de los riesgos y las oportunidades del urbanismo orientado a la economía del conocimiento. En La Ciudad del Conocimiento. Universidad Autónoma de Nuevo León; Monterrey, México
[21] Marmolejo, C.; Roca, J. (2006). Hacia un modelo teórico del comportamiento espacial de las actividades de oficina. Scripta Nova. Revista electrónica de geografía y ciencias sociales. Barcelona: Universidad de Barcelona, 15 de julio de 2006, vol. X, núm. 217
[22] Marmolejo, C.; Roca, J. (2008). La localización intrametropolitana de las actividades de la información: un análisis para la Región Metropolitana de Barcelona 1991-2001. Scripta Nova. Revista Electrónica de Geografía y Ciencias sociales. Barcelona: Universidad de Barcelona, vol. XII, núm. 268.
[23] Marmolejo, C.; Stallbohm, M. (2008). En contra de la ciudad fragmentada: ¿hacia un cambio de paradigma urbanístico en la Región Metropolitana de Barcelona? Diez años de cambios en el Mundo, en la Geografía y en las Ciencias Sociales, 1999-2008. Actas del X Coloquio Internacional de Geocrítica, Universidad de Barcelona, 26-30 de mayo de 2008.
[24] Muñiz, I. (2003). ¿Es Barcelona una ciudad policentrica?. Working Paper 03.09; Departament de Economia Aplicada; UAB.
[25] Muñiz, I. y García-López, M. (2009). Policentrismo y sectores intensivos. En Información y Conocimiento. Ciudad y Territorio, Estudios territoriales, (160):263-290.
[26] Roca, Josep. (1988). La Estructura de valores urbanos un análisis teórico-empírico. 1ª Edición. Madrid, Instituto de Estudios de Administración Local.
[27] Roca, Josep; Marmolejo, Carlos y Moix, Montserrat. (2010). Estructura Urbana y Policentrismo. Hacia una redefinición del concepto. Urban studies 11, No 5.
[28] Roca, J.(1986). La estructura de los valores urbanos un análisis técnico empírico. Primera Edición castellano, Instituto de estudios de la administración local, Madrid.
[29] Roca, J.; Clusa, J.; Marmolejo, C. (2005). El Potencial Urbanístico de la Región Metropolitana de Barcelona. Ajuntament de Barcelona, Barcelona España
[30] Roca, J.; Marmolejo, C. (2007). Dinámicas en la publicación/producción científica urbana: un análisis para las principales ciudades del mundo (1981-2002). Ciudad y territorio--Estudios territoriales.
[31] Roca, J. et al (2001). INTERREG-IIC, Estudio prospectivo del sistema urbano del sudeste europeo. Caracterización territorial y funcional de las áreas metropolitanas españolas. Informe final, Noviembre.
[32] Ruiz, M. Marmolejo, C. (2008). Hacia Una Metodología Para La Detección De Subcentros Comerciales: Un Análisis Para Barcelona y su Área Metropolitana. ACE: Arquitectura, Ciudad y Entorno, Año III, núm. 8.
[33] Sacristán, I. Roca J. (2007). Ciudad ensimismada, islarios defensivos frente a la otredad. ACE: Arquitectura, Ciudad y Entorno, Año II núm. 5.
[34] Silvestro, J.M. Roca, J. (2007). La ciudad como lugar. ACE: Arquitectura, Ciudad y Entorno, Año II núm. 3.
[35] Small, K. A. & Song, S. (1994). Population and employment densities: structure and change. Journal of Urban Economics, 36.
[36] Trullen, J. Boix, R. (2003). Barcelona, Metrópolis Policéntrica. En Red, Working paper 03 del departamento de Economía Aplicada Universidad Autónoma de Barcelona.
[37] Von Bertalanffy (1968). General Systems Theory. George Braziller, New York.
[38] Yablonsky, A. I. (1984). The development of science as an open system. In: J. M. Gvishiani (ed.), Systems Research: Methodological Problems. Oxford University Press, New York.
 Editorial
Editorial Números anteriores
Números anteriores English Versions
English Versions




